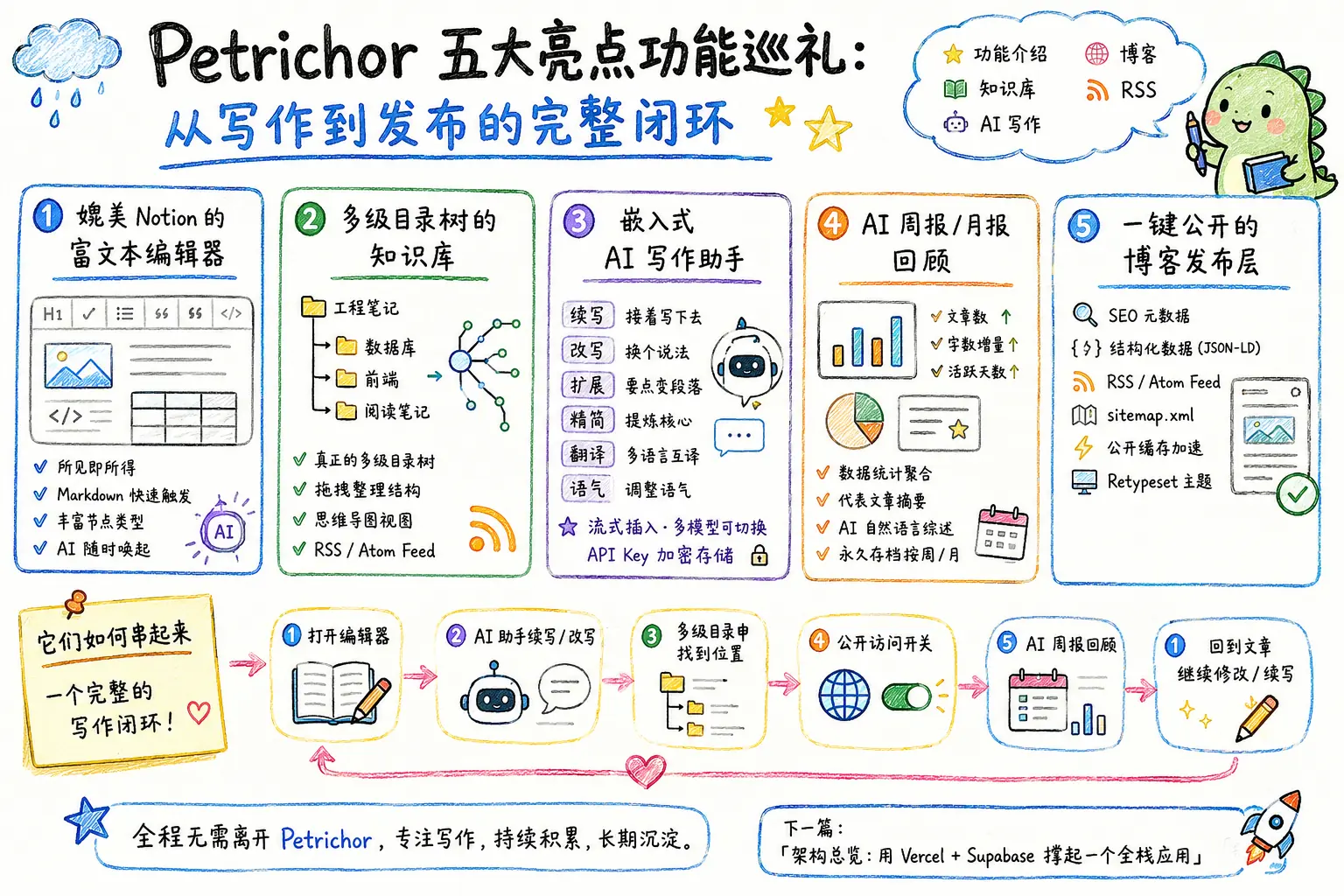
如果说上一篇讲了 Petrichor「为什么存在」,这一篇就直接展开「它具体能做什么」。下面五个功能不是简单的”特性列表”,而是把日常写作流真正闭环起来的关键节点。
亮点一:媲美 Notion 的富文本编辑器
Petrichor 的编辑器基于 PlateJS(Slate.js 之上的高级框架),不是传统的 Markdown 编辑器。这意味着你看到的就是最终样子,所见即所得;但你又随时可以用 Markdown 语法触发块转换——输入 # 空格变成 H1,- 空格变成无序列表,``` 变成代码块。
它支持的节点类型,按用途分类:
| 类别 | 节点 |
|---|---|
| 基础块 | 段落、标题(H1–H6)、有序 / 无序 / 任务列表、引用、分割线、Toggle 折叠块 |
| 代码与公式 | 多语言代码块(自带 Shiki 语法高亮)、行内代码、KaTeX 行内 / 行间数学公式 |
| 表格 | 完整的 Notion 风格表格,可调列宽、对齐方式、合并单元格 |
| 媒体 | 图片、视频、音频、文件附件、URL 嵌入(Twitter / YouTube 卡片) |
| 画布与图表 | Excalidraw 嵌入式白板、Mind Elixir 思维导图、Mermaid 流程图(通过代码块) |
| 结构辅助 | Callout 提示框、目录 TOC、双列 Column 布局、Date 日期插入、@ 用户提及 |
| 协作 | Comment 评论、Suggestion 修订(建议改动) |
打开编辑器的第一感觉应该是”和 Notion 长得几乎一样”。但有几个只有自己用过才会发现的小差异:
- 斜杠菜单(输入
/)按使用频率智能排序,常用的”标题 / 代码 / 列表”永远在最前 - 块拖拽:左侧的拖拽手柄允许你把整个块(包括嵌套结构)拖到任意位置
- 块选择:可以选中多个块批量删除 / 复制 / 拖动,键盘
↑↓在块之间跳 - AI 入口:浮动工具栏右侧、斜杠菜单首位、固定工具栏都有 AI 按钮,点哪个都能进
亮点二:多级目录树的知识库
很多博客系统的”分类”只有一层。Petrichor 的知识库是真正的多级目录树,任意层级嵌套。
每个用户可以创建多个知识库(KB),每个 KB 内部是树形结构:
工程笔记/
├── 数据库/
│ ├── PostgreSQL 索引性能调优.md
│ ├── 慢查询分析.md
│ └── 迁移脚本/
│ ├── 2026-04-add-summary.sql
│ └── ...
├── 前端/
│ ├── PlateJS 入门.md
│ └── 状态管理对比.md
└── 阅读笔记/
└── ...这种结构带来了几个具体的好处:
- 不再需要”分类 + 标签”的双重维度 —— 大粒度用目录,细粒度用标签
- 拖拽就能重新整理结构 —— 把一个节点拖到另一个分支下,子树跟着走
- 侧边栏永远反映你当前的工作上下文 —— 不会出现”我这篇文章到底属于哪个分类”的困惑
- 公开分享按子树进行 —— 你可以公开”前端”整个分支,但保留”阅读笔记”为私有
知识库内部还有几个值得一提的功能:
- 思维导图视图:把整棵子树切换成思维导图,鸟瞰知识结构
- 文章 RSS / Atom Feed:每个公开知识库自动暴露
/rss.xml和/atom.xml - 全文检索:基于 PostgreSQL 的
tsvector全文索引,中英文都能搜
亮点三:嵌入式 AI 写作助手
Petrichor 的 AI 写作助手是编辑器原生的一部分,不是”另一个聊天窗口”。
它支持的 6 种动作:
| 动作 | 输入 | 典型场景 |
|---|---|---|
| 续写 | 不选中文字,光标定位即可 | 写到一半卡住,让 AI 接着写一段 |
| 改写 | 选中一段 | 这段话表达不顺,换个说法 |
| 扩展 | 选中要点 | 把要点扩成完整段落 |
| 精简 | 选中长段 | 太啰嗦了,留核心 |
| 翻译 | 选中 + 选目标语言 | 中 → 英 / 日 / 韩 / 法 / 西 等 |
| 语气调整 | 选中 + 选语气 | 把”硬邦邦”的句子改成”友好”的 |
所有结果都是流式插入——AI 输出第一个字符开始,编辑器里就能看到内容在涨。如果生成的方向不对,可以中途按 Esc 中断,重选 / 改提示再来一次。
更重要的是这套系统的”无锁”设计:
- 你需要的不是”Petrichor 提供的 AI 模型”,而是”你自己的 OpenAI / Gemini / DeepSeek / SiliconFlow / 任意 OpenAI 兼容服务的 API Key”
- 后台「AI 配置」页可以同时配置多个模型,默认模型可以一键切换
- 每个模型都可以单独调温度(temperature)、最大 token 数、DeepSeek 的 thinking 模式开关等
填进去的 API Key 通过 AES-256-CBC + PBKDF2 在写入数据库前加密,没有 PETRICHOR_ENCRYPT_KEY 和 PETRICHOR_ENCRYPT_SALT 这两个环境变量就解不开——即便 Supabase 的数据库被人扒了一份,密钥也不会泄露。
亮点四:LLM Wiki 智能问答
当知识库累积到几十、几百篇之后,会冒出一个新的痛点:写过的东西自己也想不起来在哪了。
Petrichor 的 LLM Wiki 智能问答把整个知识库变成了一个可以对话的助手:
- 后台索引:每篇文章在保存时被切分成段落级 chunk,调用嵌入模型生成向量,写入向量库
- 提问检索:你在对话框里用自然语言提问,Petrichor 先做向量检索,找出最相关的几段原文
- LLM 回答:把检索到的原文 + 你的问题一起喂给 LLM(依然用你自己的 OpenAI / Gemini / DeepSeek Key),生成自然语言回答
- 引用原文出处:每条回答下方自动列出引用的文章与段落,点击直达原文位置
这意味着:
- 「我之前在哪篇文章里写过 Postgres 索引膨胀的处理?」→ 直接拿到答案 + 原文链接
- 「整个知识库里关于向量检索的几篇笔记,核心结论是什么?」→ 跨文章综合回答
- 「这个项目去年的部署步骤我记过笔记,具体是哪几步?」→ 找回当时的判断
它解决的是一个很现实的问题:写得越多,越容易忘记自己写过什么。LLM Wiki 让旧笔记从”沉在数据库里”变成”随叫随到”。
技术上它复用了亮点三的「AI 配置」——同一个 API Key、同一套 AES-256-CBC 加密;向量库直接走 Supabase 的 pgvector 扩展,不需要再引入额外的向量数据库。Chunk 切分策略、检索 rerank 与 token 预算控制的细节放在第 5 篇讲。
亮点五:一键公开的博客发布层
写完一篇笔记后,要把它变成公开博客,只要一个开关:
- 打开任意知识库文章
- 右上角”分享” → 勾选”公开访问”
- 选择你想暴露的字段(封面、摘要、标签、修改时间……)
- 复制公开 URL,发到任何地方
这一个开关背后,Petrichor 自动为你做了:
- SEO 元数据:自动生成
<title>/<meta description>/og:image/og:url,让微信 / Twitter / Linux Do 上贴出来的链接卡片是好看的 - 结构化数据:JSON-LD
Articleschema,帮 Google 理解这是一篇文章 - 公开 RSS / Atom Feed:
/rss.xml和/atom.xml自动包含所有公开文章 - sitemap.xml:所有公开文章自动出现在 sitemap,便于搜索引擎抓取
- 公开缓存:通过
petrichor_public_content_cache表预生成渲染后的 HTML,公开页访问不会重复读取大表 - 博客首页主题:内置一个名为 Retypeset 的极简博客首页,自动列出你所有公开文章、按标签 / 时间组织
如果你想完全自定义博客的样子,也可以——所有公开页面共用 apps/web/src/features/pages/public/ 下的几个组件,改样式 / 加自定义模块都很直接。
它们如何串起来
单看每一个功能都不算革命性,但串在一起就是一个完整的工作流:
打开编辑器(亮点一)
↓
写到一半 → 唤起 AI 助手续写 / 改写(亮点三)
↓
写完 → 在多级目录中找到合适的位置(亮点二)
↓
打开"公开访问"开关 → 自动获得 RSS / SEO / sitemap(亮点五)
↓
几个月后 → 想不起某段旧笔记在哪 → LLM Wiki 对话直接问出来(亮点四)
↓
回头打开当时的文章 → 在原地继续修改 / 续写整个循环里,你从来不用离开 Petrichor。这就是它存在的全部意义。
下一篇我们就掀开盖子,看看为了让这五个功能跑起来,底下的架构长什么样:「架构总览:用 Vercel + Supabase 撑起一个全栈应用」。