一个个人级全栈应用最容易被低估的两个模块是 AI 集成 和 认证。这两块都是”看起来简单、实际上每个边角都是坑”的代表:AI 调用有协议、限流、流式、错误重试、Key 安全;认证有会话、Cookie、OAuth、2FA、CSRF……每一个细节做不好都是事故。
这一篇我们把 Petrichor 这两块的设计和取舍讲清楚。
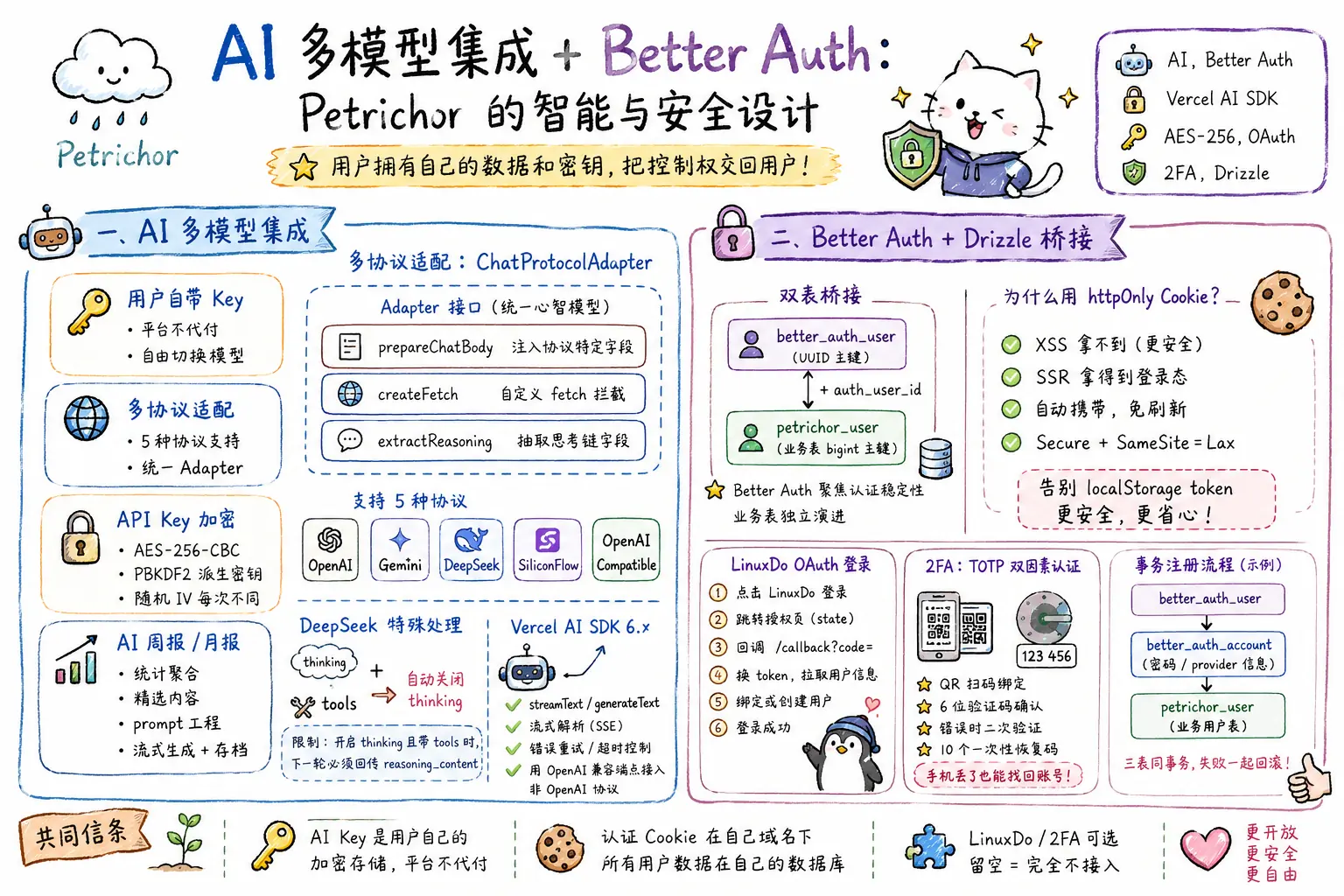
第一部分:AI 多模型集成
设计原则:用户自带 Key,平台不代付
很多 AI 产品的代付模式注定走向”涨价 → 降智 → 用户流失”的循环。Petrichor 一开始就否定了这条路:
- 所有 AI 调用都用用户自己的 API Key
- Petrichor 只负责存好 Key、做好协议适配、把流式响应转回前端
- 用户想换模型、想用某个国产小厂的新模型,不需要等 Petrichor 升级
这个决定有两个直接后果:
- 必须支持多协议——OpenAI / Gemini / DeepSeek / SiliconFlow / 各种 OpenAI 兼容端点
- 必须加密存储 API Key——明文存储是不可接受的安全姿态
下面分别讲。
多协议适配:ChatProtocolAdapter
Petrichor 在 src/server/ai/protocol-adapters.ts 里抽象了一个统一的 Adapter 接口:
export interface ChatProtocolAdapter {
readonly protocol: AiProtocol
prepareChatBody(body: unknown): unknown
createFetch(): typeof fetch | undefined
extractReasoning(message: ChatCompletionResponseMessage | undefined): string | null
}三个方法分别对应三件事:
| 方法 | 干什么 |
|---|---|
prepareChatBody | 在请求发送前修改 body,注入协议特定字段(如 DeepSeek 的 thinking 字段) |
createFetch | 返回自定义 fetch(如果某协议需要在 HTTP 层做拦截,比如把 reasoning_content 透传) |
extractReasoning | 从响应里抽出”思考链”字段(DeepSeek 的 reasoning_content / OpenAI o-series 的 reasoning) |
支持的 5 种协议都各自实现一份 Adapter:
export function resolveChatProtocolAdapter(context: ProtocolAdapterContext): ChatProtocolAdapter {
const protocol = context.protocol
if (protocol === 'DEEPSEEK') return createDeepSeekAdapter(context)
if (protocol === 'OPENAI') return createOpenAIAdapter(context)
// OPENAI_COMPAT / SILICONFLOW 默认走通用兼容
if (isLegacyDeepSeekCompatibleConfig(context)) {
return createDeepSeekAdapter(context)
}
return createOpenAICompatAdapter(context)
}上层的业务代码(AI 写作 / LLM Wiki Agent)完全不感知协议差异:它只调用 streamText({ model, system, prompt }),剩下的协议适配、reasoning 抽取、错误处理都被 Adapter 吞掉。
Vercel AI SDK 的角色
具体 HTTP 调用用的是 Vercel AI SDK 6.x(ai + @ai-sdk/openai)。它的核心价值是:
- 把”OpenAI Chat Completions”协议抽象成
streamText/generateText这样的 API - 自带流式解析(SSE → token by token)
- 错误重试、超时控制、abort signal 都封装好
对于非 OpenAI 协议(Gemini、DeepSeek),我们用 createOpenAI({ baseURL, fetch: adapter.createFetch() }) 来”伪装成 OpenAI”——把它们的 OpenAI 兼容端点接进 AI SDK。这样上层就只有一个心智模型:“所有模型都是 OpenAI 兼容”。
实际上 Gemini 不是 OpenAI 协议——但它有官方的 OpenAI 兼容端点(/v1beta/openai/chat/completions),可以通过设置 baseURL 接进来。DeepSeek 的 thinking 模式则需要在 fetch 层做改造(见下)。
DeepSeek 的特殊处理:思考模式 + 工具调用
DeepSeek-R1 / V3 系列有一个 thinking 字段控制是否开启思考链。但有个限制:开启 thinking 时如果带 tools,下一轮请求必须回传 reasoning_content 字段。AI SDK 的 OpenAI 兼容 provider 不会保留这个私有字段,导致带工具的 DeepSeek 请求二次调用时会报错。
我们的处理是:
export function prepareDeepSeekChatBody(body: unknown, options: ChatGenerationOptions) {
if (!isRecord(body)) return body
const hasTools = Array.isArray(body.tools) && body.tools.length > 0
const thinking = hasTools && options.disableDeepSeekThinkingForTools ? 'disabled' : options.deepSeekThinking
if (!thinking) return body
return { ...body, thinking: { type: thinking } }
}当请求带工具时,自动关掉 thinking。这是个折衷——DeepSeek 的工具调用 + 思考模式同时使用,需要更深度的 AI SDK 改造,对 Petrichor 这种轻量场景不值得。
API Key 加密:Spring Text Encryptor 兼容实现
用户配置 AI 模型时填入的 API Key,存进数据库前用 AES-256-CBC + PBKDF2 加密。实现见 src/server/crypto/spring-text-encryptor.ts:
const pbkdf2Iterations = 1024
const aesKeyLengthBytes = 32 // AES-256
const aesBlockSizeBytes = 16
export function encryptText(key: string, saltHex: string, plainText: string) {
const secretKey = deriveAesKey(key, saltHex) // PBKDF2 派生 32 字节密钥
const iv = randomBytes(aesBlockSizeBytes) // 每次随机 IV
const cipher = createCipheriv('aes-256-cbc', secretKey, iv)
const encrypted = Buffer.concat([cipher.update(plainText, 'utf8'), cipher.final()])
return Buffer.concat([iv, encrypted]).toString('hex') // IV + 密文,hex 编码
}几个设计要点:
- PBKDF2 派生密钥(迭代 1024 次)—— 而不是把
PETRICHOR_ENCRYPT_KEY直接当 AES 密钥用。这样即便密钥不够 32 字节也能正确派生 - 随机 IV 每次不同 —— 同一个明文每次加密产生不同密文,无法通过密文比对反推
- IV 前置存储 —— 密文格式是
iv + ciphertext,hex 编码后存数据库 - 算法兼容 Spring Security 的
TextEncryptor—— 命名上呼应 Java 后端,便于以后跨语言互通
PETRICHOR_ENCRYPT_KEY 和 PETRICHOR_ENCRYPT_SALT 都从环境变量读,只在 Vercel 函数运行时存在。数据库管理员能看到密文、看不到密钥,也就解不出明文。
LLM Wiki 智能问答:编译式 RAG 与 Agent 编排
跟 AI 配置一起串起来的还有 LLM Wiki 智能问答——它完全复用同一套用户自带 Key 与 AES-256-CBC 加密体系,只是消费端从”流式写作”换成了”Agent 多步检索”。
这块的完整实现单独成篇放在第 6 篇,这里只点核心取舍:
- 不切 chunk、不引向量库 —— Petrichor 把每篇源文档编译成结构化 Wiki 中间层(# 摘要 / ## 关键要点 / ## 实体 / ## 可回答的问题 / ## 来源),存进普通 Postgres 表
- 增量编译 —— 用
sha256(title + content)作为 sourceHash,源没变就跳过 LLM 编译 - Agent 多步阅读 —— 基于 Vercel AI SDK 的
streamText+ tool calling,11 个工具,stepCountIs(8)限步;system prompt 强制”先 Wiki 索引 → 搜 Wiki → 读具体 Wiki → 万不得已才回看源文档” - 沉淀机制 —— Agent 发现值得长期保留的新结论时调用
propose_wiki_patch,写入petrichor_kb_wiki_patch表等待用户审批;批准后才升 version 写回 Wiki - 审计 —— 所有
INGEST/PATCH_PROPOSED/PATCH_APPLIED事件落petrichor_kb_wiki_event_log表
最关键的是审批闭环这个设计:直接让 Agent 写库太危险,但不让它写又没法形成”越用越聪明”的飞轮。让它”提交 PR、等用户合并”是个折中——既允许沉淀,又能拦住误污染。
这也是为什么我们没走主流的向量 RAG 路线:对一个 5 分钟一键部署到 Vercel + Supabase 的项目,编译式 Wiki 的部署门槛(零额外依赖)和可读性(全程 markdown)都更合身。
第二部分:Better Auth + Drizzle 桥接
为什么不用 NextAuth.js / Clerk
NextAuth.js 在 App Router 时代设计上还在追赶,配置心智偏复杂;Clerk 是托管服务,依赖第三方且付费上量后不便宜。Better Auth 是一个相对新但发展很快的选择:
- 自托管,所有数据在你自己的数据库
- 原生 TypeScript + Drizzle 适配
- 默认 httpOnly Cookie 会话,不依赖前端存 token
- OAuth、2FA、邮箱验证、Magic Link 都开箱即用
Petrichor 用的是 Better Auth + @better-auth/drizzle-adapter + 业务用户表桥接。
双表桥接:业务表 + Better Auth 表
一个用户在 Petrichor 里其实是两条记录:
better_auth_user (Better Auth 主用户表,UUID 主键)
↓ auth_user_id 字段关联
petrichor_user (业务用户表,bigint 主键 + 业务字段)为什么不直接把所有字段塞 better_auth_user?因为:
- Better Auth 的 schema 是它定义的,升级时可能改字段,我们不能往里乱加业务字段
- 业务表
petrichor_user持有所有跟 Petrichor 业务相关的字段(角色、昵称、签名、绑定的 LinuxDo 账号等),独立演进 - 两表通过
petrichor_user.auth_user_id关联到better_auth_user.id
注册流程(createLocalUserWithBetterAuth)是一个事务:
const [user] = await db.transaction(async (tx) => {
await tx.insert(betterAuthUsers).values({ id: authUserId, name, email, ... })
await tx.insert(betterAuthAccounts).values({
accountId: authUserId,
providerId: "credential",
userId: authUserId,
password: passwordHash,
})
return await tx.insert(users).values({
authUserId,
email,
passwordHash,
systemRole,
userType: "LOCAL",
...
}).returning()
})三张表(better_auth_user、better_auth_account、petrichor_user)一起插入,失败一起回滚。
为什么是 httpOnly Cookie,不是 localStorage token
早期 Petrichor 把 JWT 存在 localStorage,每次请求带在 Authorization header。这个方案的问题:
- XSS 漏洞放大 — 任何注入的脚本都能直接拿到 token,发到攻击者服务器
- SSR 拿不到登录态 — 服务端渲染时浏览器
localStorage不可读,公开博客的”如果是作者本人则显示编辑入口”无法实现 - 跨域刷新麻烦 — token 过期了要手动刷,前端写一堆中间件
迁移到 Better Auth 后改用 httpOnly Cookie:
- 浏览器自动带在每次同源请求里,JS 读不到(XSS 拿不到)
Secure+SameSite=Lax+HttpOnly三件套,标准防 CSRF + 跨站攻击- SSR 拿得到 Cookie,公开页可以判断”是不是作者本人”
唯一的成本是:前端不能再持有 token 用于跨域调用。但 Petrichor 是同源应用,这个成本是 0。
LinuxDo OAuth:第三方登录的轻量接入
LinuxDo(一个国内开发者社区)有自己的 OAuth 2.0 服务。接入只用了一个文件 src/server/auth/linuxdo-handlers.ts,没有依赖第三方 OAuth 库。核心流程:
1. 用户点"用 LinuxDo 登录"
2. /api/auth/linuxdo/login → 重定向到 LinuxDo 授权页 (附 state token)
3. LinuxDo 授权回来 /api/auth/callback?code=xxx&state=yyy
4. 服务端验证 state token、用 code 换 access_token
5. 用 access_token 拉取 LinuxDo 用户信息
6. 如果该 LinuxDo 账号已绑定 Petrichor 用户 → 直接登录
否则 → 创建新用户(或绑定到已登录的本地账号)配置只需要 3 个环境变量:
PETRICHOR_LINUXDO_CLIENT_ID=...
PETRICHOR_LINUXDO_CLIENT_SECRET=...
PETRICHOR_LINUXDO_REDIRECT_URI=https://yourdomain.com/api/auth/callback第三个变量为空时 fallback 到 NEXT_PUBLIC_APP_URL + /api/auth/callback,进一步降低配置门槛。
2FA:基于 TOTP 的双因素认证
Better Auth 内置了 2FA 插件,Petrichor 用 TOTP(Google Authenticator 兼容)。数据存在 better_auth_two_factor 表:
{
id: text,
secret: text, // TOTP secret,base32 编码
backup_codes: text, // JSON 数组,一次性恢复码
verified: boolean,
user_id: text, // 关联 better_auth_user.id
}启用流程:用户在账户页点”启用 2FA” → 后端生成 secret 和 QR 码 → 用户用 Authenticator app 扫码 → 输入一次性验证码确认 → 后端 verify 通过后写库。
下次登录时:邮箱密码正确 → 检查该用户是否启用 2FA → 如果是则要求输入 6 位验证码 → 验证通过才发放 session。
恢复码(backup_codes)的设计是:用户启用 2FA 时一次性显示 10 个一次性恢复码,每个用一次就作废。手机丢了用恢复码能拿回账号。这个细节经常被忽略,但没有恢复码的 2FA 是产品事故的高发点。
总结:两个模块的共同信条
无论是 AI 还是认证,Petrichor 的实现都贯穿同一条原则:用户拥有自己的数据和密钥。
- AI Key 是用户自己的,加密存储,平台不代付
- 认证 Cookie 在自己的域名下,所有用户数据在自己的 Supabase 数据库
- LinuxDo / 2FA 都是可选的,留空就完全不接入
一个 self-hostable 的开源项目,本来就该是这样的。任何”必须经过我们的中介服务”的设计,最终都会演化成厂商绑定和数据所有权之争。Petrichor 选了一条更轴的路:把控制权交回用户。
这五篇文章下来,从产品定位到架构选型,从编辑器到 AI 与认证,Petrichor 的”底牌”基本都摊开了。如果你对其中某一块特别感兴趣,欢迎到 GitHub 仓库 翻代码——文章里讲的所有东西都对应着可读的实现。