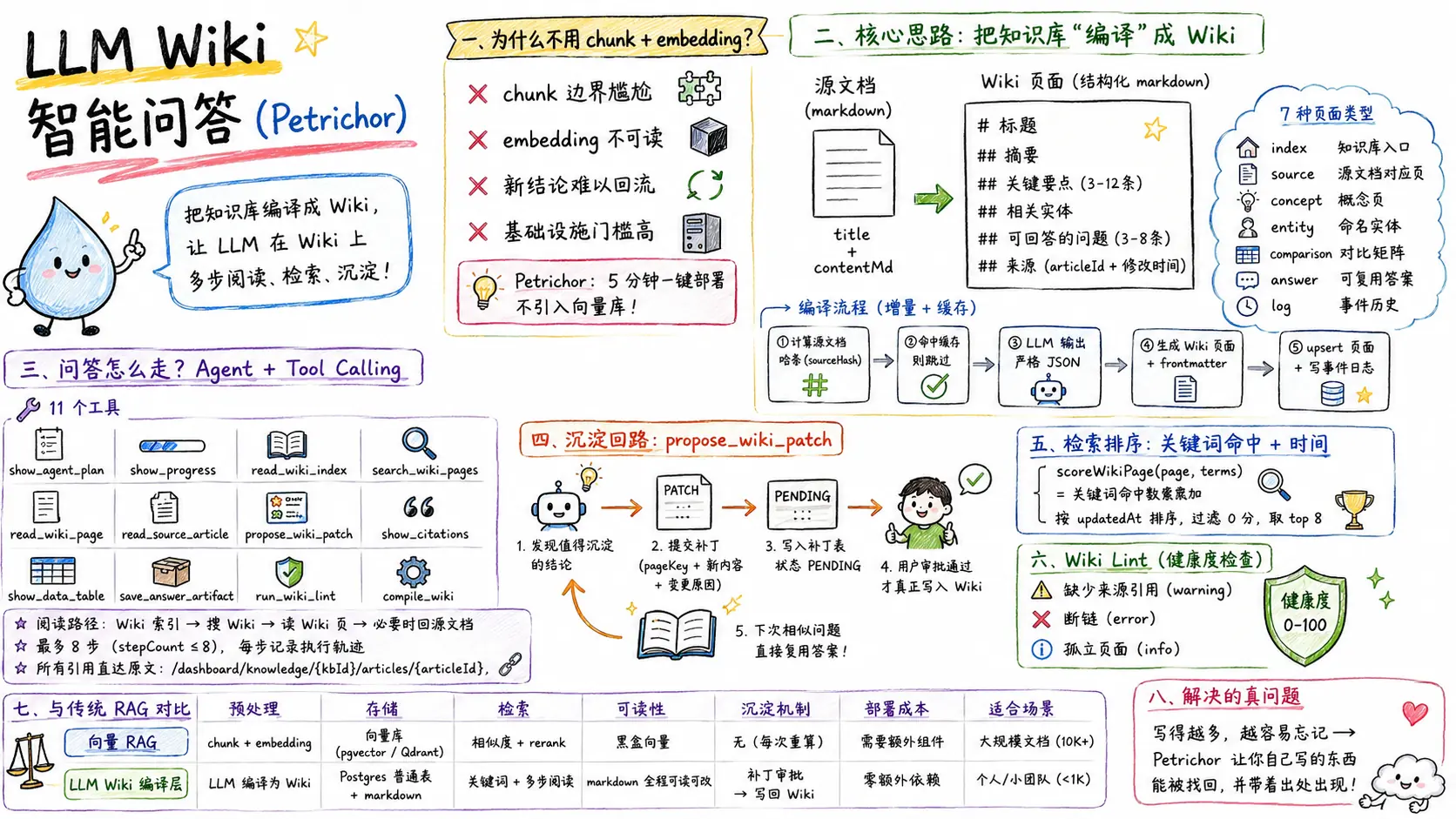
讲完 AI 多模型集成与安全设计 之后,再来拆一个 Petrichor 比较特别的子系统:LLM Wiki 智能问答。
大多数知识库问答的实现都长一个样:切 chunk → 跑 embedding → 写进向量库 → 提问时检索 top K → 塞进 prompt 让 LLM 回答。Petrichor 走的是一条不太一样的路——不引入向量库、不切 chunk,而是把整个知识库编译成一个 Wiki 中间层,再让 LLM Agent 在 Wiki 上多步阅读、检索、沉淀。
这篇文章讲清楚它的实现逻辑和这么做的取舍。
一、为什么不直接走 chunk + embedding?
向量 RAG 的链路其实有几个长期没解决好的问题:
- chunk 边界很尴尬:切得太碎丢上下文,切得太大检索精度下降,没有放之四海皆准的策略
- embedding 不可读:向量是黑盒,用户没办法直接看到、修改”被检索出来的东西”
- 新结论难以回流:模型每次回答里产生的中间结论是用完即弃的,下次同样的问题还得重算一遍
- 基础设施门槛:引入 pgvector / Qdrant / Pinecone 任何一个都要再多维护一套东西,对个人级部署不友好
Petrichor 是个 5 分钟一键部署到 Vercel + Supabase 的项目,不能为了 RAG 再绑一套向量库。所以我们换了一个思路:既然 LLM 自己就是世界上最好的”段落理解器”,为什么不用它来做预处理?
二、核心思路:把知识库”编译”成 Wiki
跟程序语言一样,Petrichor 把整个知识库视为源代码,把 Wiki 视为编译产物:
源文档 (markdown) Wiki 页面 (结构化 markdown)
───────────── ──────────────────────────
title + contentMd ──► # 标题
## 摘要
## 关键要点 (3-12 条)
## 相关实体
## 可回答的问题 (3-8 条)
## 来源 (articleId + 修改时间)每篇源文档对应一个 source 类型的 Wiki 页面。整个知识库还有一个 index 入口页面,列出所有源页面和概念页面,外加维护规则。Wiki 页面分七种 kind:
| kind | 用途 |
|---|---|
index | 知识库入口,列出所有页面 + 维护规则 |
source | 每篇源文档对应一个,由 LLM 编译生成 |
concept | 跨文档抽象出来的概念页 |
entity | 命名实体(人、库、技术名词) |
comparison | 对比矩阵 |
answer | 由 Agent 沉淀下来的可复用答案 |
log | 事件历史 |
编译核心函数是 ingestKnowledgeBaseWiki,逻辑很直接:
for (const article of articles) {
const sourceHash = stableHash(`${article.title}\n${article.contentMd}`)
const existing = await loadWikiPage(...)
// 命中缓存:源没变就跳过
if (existing && getFrontmatterSourceHash(existing) === sourceHash && !forceRebuild) {
pages.push(existing)
continue
}
// 喂给 LLM,要求输出严格 JSON
const draft = await generateArticleWikiDraft({ article })
const contentMd = renderArticleWikiPage(article, draft)
await upsertWikiPage({
pageKey: `source-${article.id}`,
kind: 'source',
contentMd,
frontmatter: { sourceHash, entities, questions },
sourceRefs: [{ articleId: article.id }],
})
}
await rebuildWikiIndex(...)几个关键设计:
- 基于哈希的增量编译:源文档没变就不重新编译,省 token 也省时间
- 强 JSON Schema:用 zod 校验 LLM 输出的四个字段(
summary/keyPoints/entities/questions),降级容错时落回本地策略(提取 markdown 标题) - frontmatter 全闭环:每个 Wiki 页面的 frontmatter 里同时存 sourceHash、实体、可回答问题,下次问答时可以直接用
- 事件日志:所有
INGEST/PATCH_PROPOSED/PATCH_APPLIED都写进petrichor_kb_wiki_event_log表,便于审计
三、问答怎么走?Agent + Tool Calling
Wiki 准备好了,问答就变成”在 Wiki 上多步阅读”的过程。Petrichor 用 Vercel AI SDK 的 streamText + tool calling 实现,给 LLM 准备了 11 个工具:
| 工具 | 作用 |
|---|---|
show_agent_plan | 复杂问题先列计划 |
show_progress | 执行中展示进度 |
read_wiki_index | 回答的第一步,读 Wiki 索引 |
search_wiki_pages | 关键词搜 Wiki 页面(不是直接搜源文档) |
read_wiki_page | 读具体某个 Wiki 页面 |
read_source_article | Wiki 不足以回答时才回看源文档 |
propose_wiki_patch | 沉淀新结论 → 提交补丁等审批 |
show_citations | 把引用渲染为可点击的卡片 |
show_data_table | 结构化结果用表格渲染 |
save_answer_artifact | 保存可复用的答案产物 |
run_wiki_lint | 检查 Wiki 健康度(缺引用 / 断链 / 孤立页) |
compile_wiki | Wiki 缺失或过期时触发编译 |
System Prompt 强制了一条阅读路径:先 Wiki 索引 → 搜 Wiki → 读具体 Wiki 页 → 万不得已才回看源文档。这套规则把 LLM 的工作范围卡在 Wiki 中间层,源文档只在核验或引用时才被加载,token 消耗远低于把整篇原文塞进 context。
stopWhen: stepCountIs(8) 限制 Agent 最多 8 步,防止无限循环。每次 tool call 完成都写 petrichor_kb_agent_step 表,前端可以实时画出执行轨迹。
回答里的每个引用都强制按 /dashboard/knowledge/{kbId}/articles/{articleId} 格式给出,点击直达原文位置——这是 Wiki 比向量 RAG 更直观的地方:用户能看到答案究竟引用了哪几段,并且点过去就是原文。
四、沉淀回路:propose_wiki_patch
这是整个设计里最有意思的一块。
传统向量 RAG 是单向的:源文档 → 向量 → 答案。答案里产生的新结论、跨文档综合、对比表,下次同样的问题还得重新算一遍。
Petrichor 通过 propose_wiki_patch 工具把这一块闭环起来:
- Agent 在回答里发现了一个”值得长期沉淀”的结论
- 调用
propose_wiki_patch,给出 pageKey、新内容、变更原因 - 服务端用简化版 unified diff 算出变更,写入
petrichor_kb_wiki_patch表,状态PENDING - 用户在 Wiki 仪表盘看到待审批补丁,点确认才会真正写入 Wiki 页面(升 version、记 event_log)
- 下一次有人问到类似问题,Wiki 索引里已经有了这条沉淀,Agent 可以直接读
concept或answer页面拿到答案
这种补丁审批的设计来自对 Agent 的不信任:直接让模型写库太危险,但完全不让它写又没法形成”越用越聪明”的飞轮。让它”提交 PR”是个折中——既允许沉淀,又能拦住误污染。
五、检索排序:没用向量,但够用
Wiki 页面的”搜索”用的是 scoreWikiPage,简单的关键词命中数排序:
function scoreWikiPage(page, terms) {
const haystack = `${page.title}\n${page.pageKey}\n${page.summary}\n${page.contentMd}`.toLowerCase()
return terms.reduce((score, term) => score + (haystack.includes(term) ? 1 : 0), 0)
}加上按 updatedAt 二次排序,再把分数 0 的页面过滤掉,取 top 8 给 Agent。
这是个有意识的简化:
- LLM 编译时已经把核心信息浓缩到 summary / keyPoints / entities,关键词检索的 recall 反而比直接搜源文档高
- Agent 多步检索 + 自己决定再读哪些页面,单步召回不需要完美
- 不依赖向量库 = 部署门槛低 = 用户能在 Vercel 上零成本跑起来
如果将来想升级,把 scoreWikiPage 换成 pgvector 的 cosine similarity 就是几十行代码的事——整个 Agent 层不用动,因为它消费的接口是 searchWikiPagesForAgent,不关心底层。
六、健康度:Wiki Lint
runWikiLint 把 Wiki 当作一个”代码库”做静态分析:
- 缺少来源引用(warning):source 类型以外的页面如果没挂任何
source_ref,可能是 Agent 凭空生成的 - 断链(error):链接指向的 pageKey 不存在
- 孤立页面(info):没有被任何页面引用的页面
综合给一个 0-100 的健康度分数。这套机制和 Wiki 编译、补丁审批一起,构成了 Petrichor 对 Agent 输出的”质量护栏”。
七、跟传统 RAG 的对比
| 维度 | 向量 RAG | LLM Wiki 编译层 |
|---|---|---|
| 预处理 | chunk 切分 + embedding | LLM 编译为结构化 Wiki |
| 存储 | 向量库 (pgvector / Qdrant) | Postgres 普通表 + markdown |
| 检索 | 余弦相似度 + rerank | 关键词命中 + LLM 多步阅读 |
| 可读性 | 黑盒向量 | markdown 全程可读可改 |
| 沉淀机制 | 无(每次重算) | 补丁审批 → 写回 Wiki |
| 部署成本 | 需要额外组件 | 零额外依赖 |
| 适合场景 | 大规模文档 (10K+) | 个人/小团队知识库 (<1K) |
并不是说向量 RAG 不好,而是对一个 5 分钟一键部署的个人知识库,编译式 Wiki 是更合适的形态:用户的资产是”自己写过的几百篇笔记”,不是”互联网级的文档语料”,LLM 直接编译完全压得下来。
八、它解决的真问题
回到一开始的痛点:
写得越多,越容易忘记自己写过什么。
Petrichor 的 LLM Wiki 智能问答其实是在解决一个很私人的问题:让你几个月前随手记下的某个判断能在你需要的时候被找回来,并且带着出处一起出现。
它不追求”通用知识助手”的宏大叙事——它就是你自己写的东西的一个会说话的索引。
源代码主要文件:
apps/web/src/server/kb/wiki-agent-logic.ts:编译、检索、补丁、lint 的核心逻辑apps/web/app/api/kb/agent/chat/route.ts:Vercel AI SDK 的 Agent 编排apps/web/app/api/kb/wiki/*:编译、列表、详情、健康检查的 HTTP 端点petrichor_kb_wiki_page / _link / _source_ref / _patch / _event_log:5 张表
如果你也在折腾个人级的知识库 RAG,欢迎去 GitHub 翻这块代码——它跑得不会比向量库版本慢,但维护和理解的成本低很多。