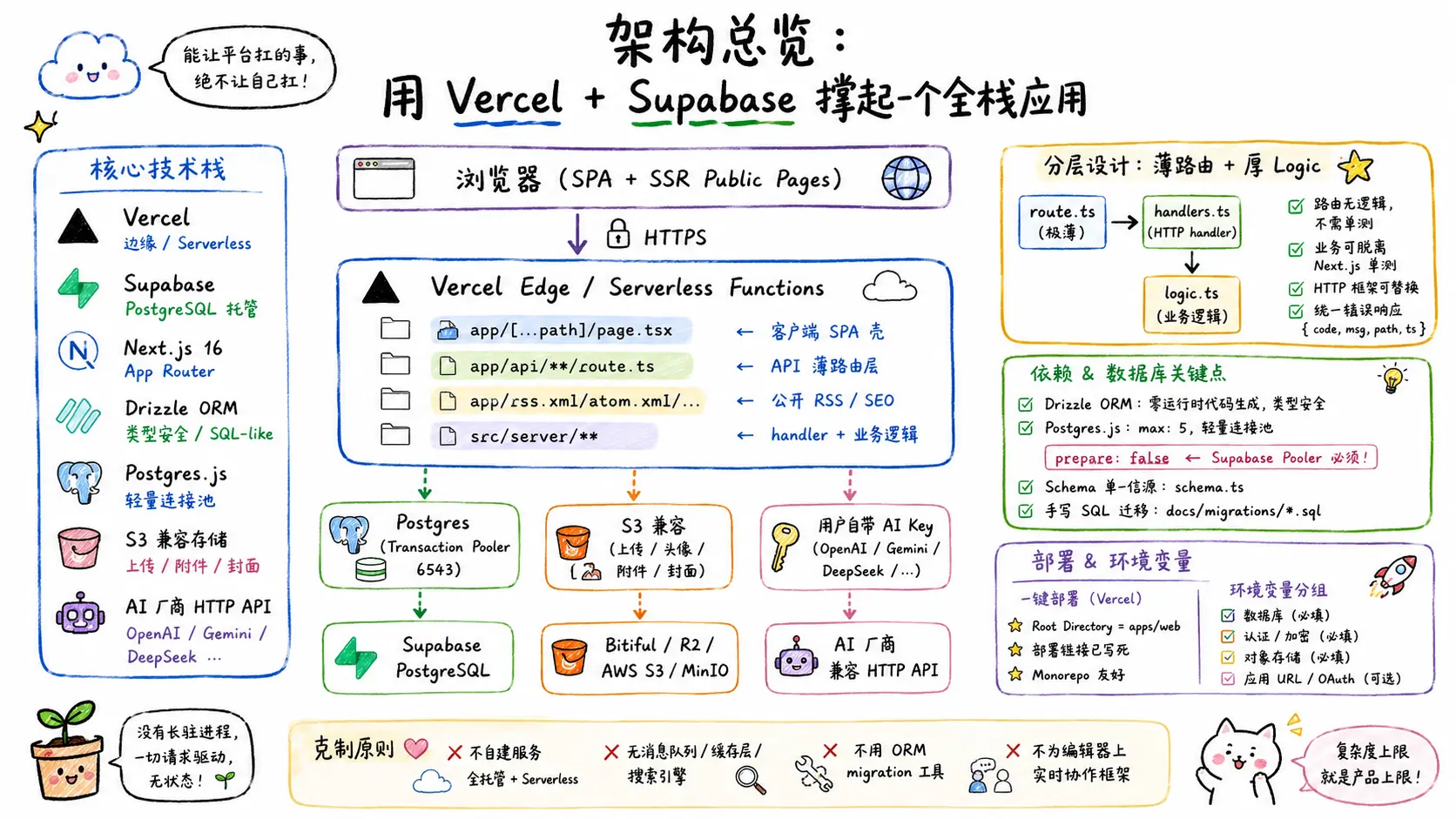
如果让我用一句话概括 Petrichor 的架构选型原则:能让平台扛的事,绝不让自己扛。
这一篇我们打开盖子,看看为了支撑前一篇讲的五大功能,底下的技术栈是怎么搭起来的,以及每个选型背后的考虑。
整体结构
Petrichor 不是一个传统的”前后端分离 + 自部署”项目。它的运行形态更接近”一个跑在 Vercel 边缘上的 Next.js 全栈应用,背后挂一个 Supabase Postgres”。
┌─────────────────────────────────────────────────────────┐
│ 浏览器 (SPA + SSR Public Pages) │
└────────────┬────────────────────────────────────────────┘
│ HTTPS
▼
┌─────────────────────────────────────────────────────────┐
│ Vercel Edge / Serverless Functions │
│ ├─ app/[...path]/page.tsx ← 客户端 SPA 壳 │
│ ├─ app/api/**/route.ts ← API 薄路由层 │
│ ├─ app/rss.xml/atom.xml/... ← 公开 RSS / SEO │
│ └─ src/server/** ← handler + 业务逻辑 │
└──────┬────────────────────┬─────────────────────┬───────┘
│ Postgres │ S3 兼容 │ 用户自带 AI Key
│ (Transaction │ (上传 / 头像 / │ (OpenAI/Gemini/
│ Pooler 6543) │ 附件 / 封面) │ DeepSeek/...)
▼ ▼ ▼
┌──────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ Supabase │ │ Bitiful / R2 / │ │ AI 厂商 OpenAI │
│ PostgreSQL │ │ AWS S3 / MinIO │ │ 兼容 HTTP API │
└──────────────┘ └──────────────────┘ └─────────────────┘整套系统没有任何长驻进程——Vercel 函数都是请求触发的、无状态的。这是一个重要的隐性约束,后面会看到它如何影响我们对数据库连接、缓存、AI 调用的处理。
Monorepo:pnpm workspace
仓库根是一个 pnpm workspace,目前只挂了一个应用:
.
├── apps/
│ └── web/ # Next.js 全栈应用
├── docs/ # SQL 迁移 + 文档
├── package.json # 根 package(workspace 声明)
├── pnpm-workspace.yaml
└── pnpm-lock.yaml为什么用 monorepo 而不是单仓单包?理由很务实:
- 早期项目预留了未来可能拆出
apps/desktop(Tauri 客户端)或packages/shared共享类型库的扩展空间 - pnpm workspace 的隔离能力让”安装一次依赖、所有子项目共享 node_modules”成为可能,CI 构建时间更短
- Vercel 对 monorepo 友好——只需要把 Root Directory 设为
apps/web,部署按钮 URL 里加root-directory=apps%2Fweb就行
根 package.json 用 pnpm --filter 把命令转发到子项目:
{
"scripts": {
"dev": "pnpm --filter @petrichor/web dev",
"build": "pnpm --filter @petrichor/web build",
"test": "pnpm --filter @petrichor/web test"
}
}这样开发者在仓库根就能跑所有命令,不需要 cd 进去。
Next.js App Router:薄路由 + 厚 handler 的分层
Petrichor 用 Next.js 16 的 App Router,但 API 路由文件保持极薄,所有业务逻辑都在 src/server/** 里。
一个典型的 route.ts 长这样:
// app/api/kb/list/route.ts
export { listKnowledgeBases as POST } from '@/server/kb/handlers'仅此一行。
而 src/server/kb/handlers.ts 里才是真正的处理逻辑:
export async function listKnowledgeBases(request: NextRequest) {
try {
const user = await requireCurrentUser(request)
const input = listKnowledgeBasesSchema.parse(await readJson(request))
const result = await listKnowledgeBasesByUser({
userId: user.id,
...input
})
return ok(tableData(result.items, result.total))
} catch (error) {
return toErrorResponse(error, request.nextUrl.pathname)
}
}这种分层有几个好处:
- route.ts 永远不需要做单元测试 —— 它没有逻辑可测
- 业务逻辑可以脱离 Next.js 环境单测 —— Vitest 直接对
src/server/kb/logic.ts调用,不需要 mockNextRequest - HTTP 框架可替换 —— 如果某天想从 Next.js Route Handler 迁移到 Hono 或自建 Fastify,只需要替换路由壳
- 统一的错误响应 ——
toErrorResponse把任意异常变成{ code, msg, path, timestamp },不泄露内部细节
服务端的目录约定:
src/server/
├── kb/ # 知识库模块
│ ├── handlers.ts # HTTP handler(薄)
│ ├── logic.ts # 业务逻辑(厚,可测试)
│ ├── logic.test.ts
│ └── mappers.ts # 数据库 → API 响应的映射
├── auth/ # 认证:邮箱密码、Better Auth 桥接、LinuxDo OAuth
├── ai/ # AI 模型配置 / 写作 / LLM Wiki Agent
├── upload/ # S3 预签名上传
├── notification/
├── db/
│ ├── schema.ts # Drizzle 表结构(单一信源)
│ ├── client.ts # 连接池
│ └── full-migration.ts # 生成完整初始化 SQL
└── http/
├── response.ts # ok / tableData / toErrorResponse
└── pagination.ts # 通用分页参数解析每个业务模块都遵守”handlers / logic / mappers / tests”的 4 文件结构。这样的好处是,新人接手任意一个模块都知道去哪找东西。
客户端:SPA 入口 + SSR 公开页混合
Next.js 标准做法是每个 page 都做 SSR。Petrichor 走了一条混合路线:
- 登录后的工作区(仪表盘 / 知识库编辑 / AI 配置 / 后台管理……)是一个客户端 SPA,通过
app/[...path]/page.tsx这个 catch-all 路由动态加载apps/web/src/client-app.tsx,内部用react-router-dom管理路由 - 公开博客页(文章详情 / 博客首页 / RSS / sitemap)才走真正的 SSR
为什么这么分?
| 维度 | 工作区 | 公开博客 |
|---|---|---|
| 用户 | 已登录、知道自己在哪 | 来自搜索引擎 / 分享链接 |
| 首屏速度 | 不需要——已经登录的人不会在意第一次加载多 200ms | 必须快 —— SEO、首屏 LCP 都要顾 |
| SEO | 不需要——后台页本来就 noindex | 必须 |
| 复杂度 | 高,状态多,需要 React Query / Zustand | 低,主要是渲染 |
这个分割让我们避免了”为了仪表盘的 SEO 而把整个工作区都跑 SSR”这种过度工程。SPA 部分的页面切换不再走 Next.js 的路由——本质上它们用同一个 React 树,路由切换是纯客户端的。
数据层:Drizzle + Postgres.js + Supabase Transaction Pooler
数据库选型上有几个关键决定:
1. Drizzle ORM 而非 Prisma
Drizzle 的好处是:
- 零运行时代码生成,schema 就是 TS 文件,类型推断完全静态
- SQL-like API,写起来更接近 SQL,调试时一眼能看出生成的查询
- 比 Prisma 启动快得多 —— 这在 Serverless 场景下意义重大
2. Postgres.js 而非 node-postgres
我们用 drizzle-orm/postgres-js 的驱动,背后是 postgres 这个轻量库。配置只有 13 行:
// apps/web/src/server/db/client.ts
import { drizzle } from 'drizzle-orm/postgres-js'
import postgres from 'postgres'
let client: postgres.Sql | null = null
let db: ReturnType<typeof drizzle<typeof schema>> | null = null
export function getSqlClient() {
client ??= postgres(getServerConfig().databaseUrl, {
max: 5,
prepare: false
})
return client
}注意两个细节:
max: 5—— Vercel Serverless 函数每个实例最多 5 个连接,避免连接风暴prepare: false—— 这是 Supabase Transaction Pooler(端口 6543)的硬性要求
3. 为什么必须 prepare: false?
Supabase 的 Transaction Pooler 用的是 PgBouncer transaction 模式。在这个模式下,多个客户端连接复用同一个底层 Postgres 连接,预编译语句(prepared statements)会跨连接错乱。
如果不关掉 prepare,你会看到一些极其玄学的报错:
PostgresError: prepared statement "s1" already exists而且这个错只在并发量上来后才出现,本地开发可能永远不复现。所以一开始就要把 prepare: false 写死。
4. Schema 是单一信源
整个项目的 schema 定义都在 apps/web/src/server/db/schema.ts 一个文件里:
export const users = pgTable(
'petrichor_user',
{
id: bigint('id', { mode: 'bigint' }).primaryKey().generatedAlwaysAsIdentity(),
authUserId: text('auth_user_id'),
email: text('email').notNull(),
passwordHash: text('password_hash').notNull(),
systemRole: text('system_role').notNull().default('USER')
// ...
},
table => [uniqueIndex('ux_petrichor_user_email').on(table.email)]
)但我们不直接用 Drizzle 的 migration——而是写了一个 scripts/print-initial-migration.ts:
pnpm --silent --filter @petrichor/web db:sql > petrichor-init.sql这个脚本会读 schema,输出一段幂等的初始化 SQL(带 if not exists / on conflict do nothing),可以在 Supabase SQL Editor 一次性执行,也可以在已有数据库上重复执行不出错。
增量变更则放在 docs/migrations/<日期>-<功能>.sql,每个都是手写、人审过的 SQL。我们故意没有用 Drizzle 的自动 migration——生产数据库的变更必须有人看一眼,自动化在这里反而是风险。
部署:Vercel 一键化
部署部分的设计核心是”让用户一次都不用 cd 到子目录”:
- 根目录有一个
pnpm-workspace.yaml,Vercel 自动识别为 monorepo - Vercel 部署时 Root Directory 设置为
apps/web,构建从该目录开始 - 部署按钮 URL 里把这个配置写死成
&root-directory=apps%2Fweb,用户点一下就自动设好
环境变量被严格分成四组:
| 组 | 变量 | 是否必填 |
|---|---|---|
| 数据库 | DATABASE_URL | ✅ |
| 认证 / 加密 | SESSION_SECRET、PETRICHOR_ENCRYPT_KEY、PETRICHOR_ENCRYPT_SALT | ✅ |
| 对象存储 | S3_ENDPOINT / S3_REGION / S3_BUCKET / S3_ACCESS_KEY_ID / S3_SECRET_ACCESS_KEY | ✅ |
| 应用 URL / 注册策略 / OAuth | NEXT_PUBLIC_APP_URL、NEXT_PUBLIC_REGISTER_ENABLED、PETRICHOR_LINUXDO_* | ❌(有 fallback) |
所有变量都经过 Zod schema 校验(src/config/server.ts),启动时如果缺关键值或格式错,Vercel 会在构建阶段就报错,不会跑到运行时才炸。
总结:架构里的克制
回过头看,这套架构里最值得说的不是”用了什么”,而是”没做什么”:
- 没有自建任何后端服务 —— Postgres 用 Supabase 托管,函数跑在 Vercel,对象存储用任何 S3 兼容服务
- 没有引入消息队列、缓存层、搜索引擎 —— Postgres 的
tsvector解决全文搜索,petrichor_public_content_cache表解决公开页缓存 - 没有引入 ORM 的 migration 工具 —— 手写 SQL 更可控,迁移历史更可读
- 没有为编辑器搭实时协作框架 —— 个人 / 小团队的写作场景里,单人编辑足够,多人评论 / Suggestion 已经覆盖了协作的 80%
对于一个目标”个人 / 小团队”的工具,复杂度上限就是产品上限。每多一层架构,部署难度和维护成本都是指数级的。
下一篇我们聚焦在编辑器层:「PlateJS 重度玩家手记:构建一个媲美 Notion 的编辑器」。